

It’s common for developers working at large organizations to covet the agility and autonomy that allows smaller organizations to move fast. Improving organizational efficiency while operating at scale can be challenging. If you take an approach that is too top-down, you risk squashing experimentation. Meanwhile, working from the ground up can result in too many local optimizations that squander the opportunity to build upon successes across the organization. Additionally, we wanted to ensure that the overhead of managing such an alignment stays as low as possible.
In this Guide, you will learn:
What is GitOps?
How can GitOps benefit your organization?
How Blue Yonder uses GitOps to manage some of its operations
The origin story
At Blue Yonder, we strive to grow by minimizing bottlenecks. We want to adopt best-of-breed technologies—even if we are not experts in them—and focus our efforts on Blue Yonder's raison d’être: providing an AI-driven supply chain platform for our customers. We aim for our support staff and product/services teams to manage as few services and tools as possible. And let me clarify a point of invisible toil here. There is often a misconception that companies can easily run their own open source deployments or hosted Docker/Kubernetes services. Although you can often run these services with relatively cheap cloud resources, folks forget the operational overhead. This includes having staff available to manage, tune, and support these critical systems. Moreover, with teams working globally, you need to do it in a follow-the-sun capacity.
For years, Blue Yonder managed many of these systems internally, from code management, static code scanning (SAST), and dynamic code scanning (DAST) to CI/CD workers. As we evaluated the transition of these support systems to cloud vendor management, we considered criteria such as staff familiarity (productivity is king), security, extensibility, and scalability. The choice was clear to us: The tea leaves of our business goals pointed us to GitHub.
Trouble in paradise
Everyone knows GitHub, right? Problem solved!? It’s one thing to understand how to utilize GitHub for open source projects or small organizations with private repositories, but it becomes more complex as you try to drive best practices throughout an organization of thousands of people. Managing the process involves the following:
Outline permissions across thousands of repositories (multi-repo) or complex mono repos.
Drive the adoption of DevOps methodologies, such as Trunk Based Development and Clean Code. These software engineering best practices will improve DORA metrics of Deployment Frequency, Lead Time for Changes, and Change Failure Rate.
Adhere to legal and/or security regulations such as SOC 2 and SOX, which ensures we’re not in breach of our corporate legal and regulatory obligations.
Drive collaboration, code reuse, and innovation through innersource practices.
Make it easy and familiar for developers to move from one team to another to balance resources. For example, as a set of microservices matures, it might need fewer folks to operate and maintain it. Some team members can easily join other teams and be productive in no time as they are familiar with the standards, methodologies, and technology stacks used throughout the company.
Improve the time to first meaningful pull request. Never underestimate the feeling of accomplishment by newbies.
Achieve all of the above with a lean management overhead.
Although GitHub provides organizational administration, it relies on a flat structure. The illustration below describes the organizational structure of Blue Yonder's engineering groups.
Note: There are many more product segments and product teams, but you get the idea.
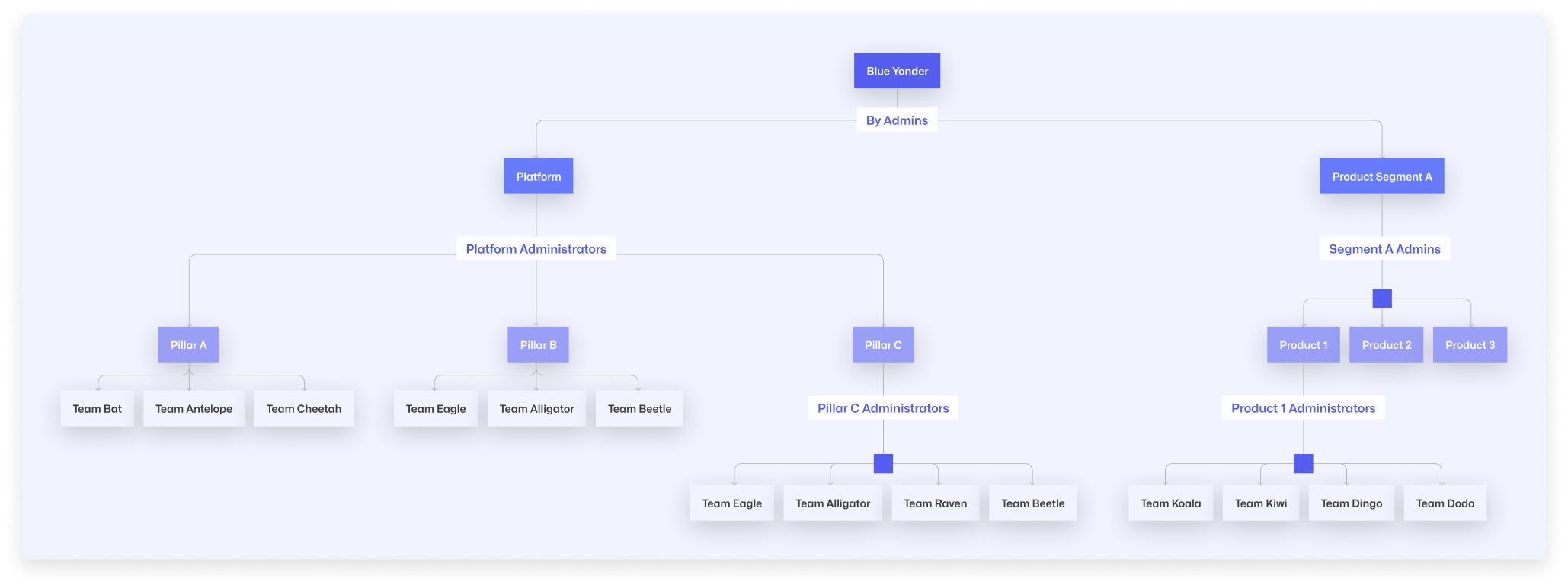
It’s challenging to balance autonomy and governance in a way that addresses business needs while allowing innovation to breathe, and complexity will look different for every organization. You may have secrets available to some groups and not others, or a complex map of modules, services, and applications that every team utilizes differently. To further complicate the situation, the relationship between these secrets, services, and teams is constantly changing. GitOps provides a way to manage these dependencies while keeping admin oversight to a minimum.
What is GitOps?
As some of you may have guessed, It's the combination of Git practices and Operations. More specifically, it’s the ability to manage your operations by defining a system’s desired state–the structures, configuration, infrastructure, and interactions as Git operations within repositories. GitOps evolved from DevOps practices. It allows you to define almost any structure you'd like, as long as you can use underlying APIs to reflect it (such as in the case of GitHub APIs).
The GitOps Working Group, of which GitHub is a member of, formalizes GitOps as:
Declarative: A system managed by GitOps must have its desired state expressed declaratively.
Versioned and immutable: The desired state is stored in a way that enforces immutability and versioning, and retains a complete version history.
Pulled automatically: Software agents automatically pull the desired state declarations from the source.
Continuously reconciled: Software agents continuously observe the actual system state and attempt to apply the desired state.
We can use familiar and battle-tested git processes to manage operational workflows and structures (which, in many cases, are specific to one organization or another). For Blue Yonder, this includes representing org structures and processes as JSON/YAML files and following git-specific naming conventions and pipelines.
Further, we can use mechanisms such as CI/CD to accept requests and create new repos. We can also generate repos that adhere to our best practices, naming conventions, and ownership standards. Additionally, the process encourages anyone to suggest improvement to the workflow. This emphasis on evolution illustrates one of the five ideals of DevOps: improvement of daily work.
Let’s take a look at how we can pair engineering best practices with GitOps automation. The following are not mandatory in GitOps, but the concepts of GitOps allow us to formalize and automate the best practices. In this case, the automation of these best practices allows all teams at Blue Yonder to standardize easily on the following:
Repos created at Blue Yonder include the standard static files (as GitHub template repos do) and automatically generated files specific to the repo (e.g., CODEOWNERS files to control who can review pull requests (PRs)).
Security requirements checks
Code quality branch protection checks
Testing checks
At Blue Yonder, we work in team sets, a well-defined group of multiple teams working together to administer, collaborate, and contribute to a set of repositories.
What is a team set?
Team sets include three types of members:
Admins handle the management of the repository
Collaborators contribute to repositories and are tasked with approving PRs to be merged to main
Contributors add contributions to repositories but require collaborator approval to merge changes
As you may have noticed, we are weaving our very own administration model to be low-touch and adhere to our best practices, which does not come out of the box. Lucky enough, GitHub supports a plethora of APIs that allow you to re-imagine what your organization will look like through the lens of GitOps.
GitOps: the Blue Yonder way
As a general rule of thumb, at Blue Yonder we try to maintain the delicate balance between governance of best practices/requirements, and maintaining team autonomy through a slim operational management model. There are many ways you can achieve your preferred management structure when the data model of a vendor, such as GitHub, does not provide it out of the box. One of the more straightforward ways is to use naming conventions to make the data model work for you. The catch here is that you'll have to curate the processes used by these naming conventions. Considering our teams’ organizational structure, the naming conventions we landed on are:
<segment>-<product>-<module>
Example: creatures-dragonnify-fire-breathing-service. The structure used for segments, products, and teams is included as a JSON configuration file in our organization’s GitOps repository.
{
"creatures": {
"name": "Creatures segment",
"products": {
"dragonnify": "Dragonnify product",
Anyone that wants to add or change a team just submits a PR on this file. A small group of collaborators referred to in the CODEOWNERS file can then do a quick review. If the JSON linting passes, which is done automatically on each file, the file can be merged to main.
What about that team set?
As mentioned previously, we assign at least one team set to every repo to ensure as much team autonomy as possible while adequately defining responsibilities. The concept of team sets does not currently exist in GitHub’s standard implementation. As such, in our Blue Yonder GitOps.org repo, we define a JSON file to allow our staff to create team sets.
As repos are created, the Blue Yonder GitOps automation workflow will automatically associate team sets. A team set is created using standard git tools that commit changes to our JSON definition file, then submit a PR (reviewed by the development support team), and assign it to each newly created repo.
Each team set can have one or more maintainers, with the ability to add members later. To reiterate, each team set is composed of three GitHub teams with an identical prefix. An example of these team set–defining files can be found here:
[
{
"namePrefix": "Guardians of The Galaxy",
"maintainers": [
"Star-Lord_ghub",
"Gamora-Zen_ghub",
The above will result in three teams:
Guardians of The Galaxy Admins
Guardians of The Galaxy Collaborators
Guardians of The Galaxy Contributors
Team set organization files include the same content as outlined for repos; a JSON file–defining team structure. Once the PR to change the file is approved, one of our GitOps GitHub Action workflows will automatically read the file, check for changes from the previous version, and then will add, remove, or change the team set in the organization. Let's create repos the way we want them
First, we make sure no one has the ability to create repos directly using GitHub, ensuring we stay aligned as a company. Second, we supply team members with a GitHub Action pipeline that creates new repositories that align with Blue Yonder naming conventions and team set structures.
Anyone at Blue Yonder can create such a repo. As part of the automation, we:
Validate team existence and manage assignments to repos
Validate repo naming
Create branch protection rules
Generate a CODEOWNERS file and assign it to the collaborators of the team set assigned to the repo
Using our MS-Teams channels, notify the creator that:
Creation was successful (includes Blue Yonder usage guidelines and a link to the newly created repository), OR
Creation failed and the detailed reason on why it failed (maybe a wrong team set or naming convention was specified)
Many of the processes and structures above are specific to BlueYonder but you can achieve your own GitOps in a similar way. I encourage you to:
Identify your desired processes and existing organizational structures and connections.
Create a representation of these structures in source files such as JSON or YAML. Feel free to break them down further to simplify assigning—use the CODEOWNERS file to delegate to teams throughout your organization.
Handle tailored repo creation, secret/repo mapping, teams/repo mapping, and organizational structure with GitHub Actions. Use the files above and the GitHub API to facilitate this.
Out-of-the-box solutions will work for some organizations. For others, it will be like trying to fit a square peg in a round hole. Using the tools provided by GitHub and methodologies like GitOps allows you to build a solution that fits like a glove. As mentioned, the code reflecting the concept of this article can be found in this repo:
We hope this has inspired you to start your own journey to balance governance and autonomy and break silos, delegate more efficiently, and eliminate bottlenecks in your organization.


