


Also in Developer Stories
Elevating others and making open source approachable
Documentation exists in many different forms. There is, of course, traditional documentation—such as tutorials and manuals that live outside of a codebase. But there are other ways to capture and codify procedures or share context-specific knowledge, including code comments, config files, templates, and automation to increase consistency.
These forms of documentation are powerful because they exist in the places where you’re most likely to use them, whether that’s within a chunk of code or inside your IDE. Taking time to learn about different ways to store and present information can save your future-self time and hassle, and help colleagues or open source contributors work more effectively.
Maintain configuration files remotely
How many hours would it take you to set up a new computer with your preferred configurations? If you don’t want to spend hours starting from scratch on a new device you can save time by maintaining environment setup files that reflect and document your preferred configurations and automating some of the installation and configuration processes of setting up a new computer.
Various types of software configurations are typically stored in dotfiles which are files that are prepended with a dot. For example,`.gitignore` is a particular type of dotfile that ensures that files that match a certain filename or extension are not tracked by version control without having to actively make that decision whenever adding new files to version control. The repo gitignore contains helpful .gitignore templates that you may want to adapt to your projects. If you are using similar technologies across projects then you will likely want to use the same or very similar .gitignore configuration amongst different repositories. Readily having access to dotfiles that are tailored to your specific requirements and preferences will allow you to get up to speed quickly when setting up a new project or even a new computer if you unexpectedly need to switch to a new device.
Dotfiles are generally plain text and can be stored in version control, however, it’s important to note they should only be stored in remote version control if they don’t include sensitive information like secret environment variables—unless they can be stored in a version that is entirely sanitized of any information that should not be publicly available. It’s really important to treat any sensitive information that is committed to remote version control as compromised. If you accidentally commit information that should not be publicly accessible on GitHub you should follow the steps outlined here. However, the article notes that if there are forks or clones of your repo that you should still assume there is a risk that the sensitive information has been compromised which means it is probably best to regenerate any authentication-related keys.
There is an active community of folks who maintain and share their dotfiles on GitHub so there’s no shortage of examples of how other developers organize and use their dotfiles to enhance their workflow. If you are interested in maintaining various dotfiles there is an unofficial guide to dotfiles on GitHub. You can also draw inspiration for your configurations from others who have shared their dotfiles like the software consultancy Thoughtbot.
Automation can make the process of putting configuration files to use easier. For example, I’ve codified some of my MacOS environment decisions by writing a Bash script I wrote to install Homebrew—a package manager for MacOS and Linux—which in turn installs 42 applications I generally use. Homebrew has casks that can be used to install popular programs like Spotify with `brew install—cask spotify`. You can learn what software is available for download via Homebrew by visiting Homebrew Formulae. I was inspired to set up a Homebrew script to install applications based on the collection of scripts (zellwk/dotfiles) that the developer Zell Liew uses to quickly set up a new MacBook with the proper applications, credentials, MacOS settings, etc. His repository contains scripts that use Homebrew to install applications, NPM to install CLIs, and a script to determine macOS settings. Within my `dotfiles` repo I also maintain my VSCode settings to quickly move my settings from one VSCode environment to another although if you use the same GitHub account across devices then you can sign in to have your VSCode settings auto-sync.
Automate file creation for standardization
Have you ever copied and pasted the same boilerplate code for multiple files at once? I've found that when creating components, at a minimum, I generally have to create an assortment of files that may include: the index file, test files, related assets, related translations, README, storybook file, etc. Each of these files generally have to follow certain conventions in terms of how dates are formatted, the casing used for filenames, the component or function syntax, etc.
If you have strict conventions for how files should be named, structured, and organized in ways that can't be adequately captured by linting, then I recommend looking into whether automating file creation is worth your while. From my exploration, there are some relatively lightweight options, including automating file creation with PlopJS or using tools like Makefiles to conform to a predetermined template. As a contributor, I've found that I can more quickly contribute new components to an unfamiliar repository that has a generator for creating new components. There are some conventions and standards that can be baked into a template that otherwise would be difficult to capture without reading very detailed documentation or heavily referencing other components. Being able to run a command to auto-generate the files for a new component has allowed me to more quickly understand the conventions that are enforced in an unfamiliar project. These templates reduce the amount of copying and pasting involved in getting the 'Hello World' version of a component that follows all of the conventions ready, is more accurate than manually piecing together various conventions, and encourages more consistency of how various design patterns are implemented.
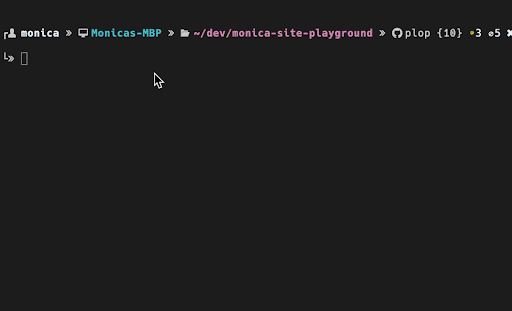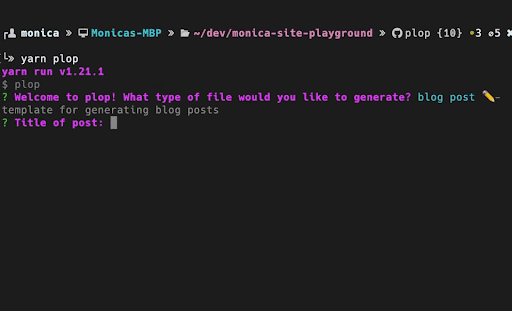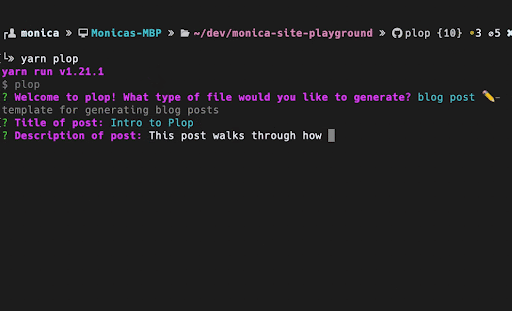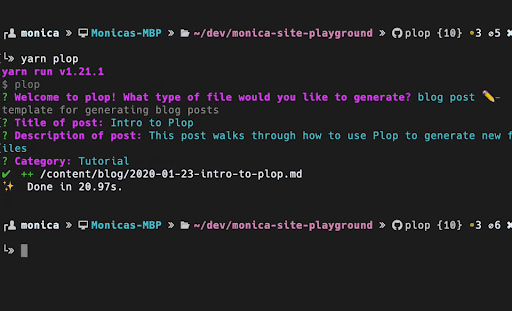
When exploring the introduction of templates to a project it is important to determine whether the template will actually save you time based on how often the task will need to be done, how long it will take to implement the automation, and how much maintenance the template may require overtime to ensure there is minimal drift between the template and the desired conventions. I found the PlopJS library, a micro-generator, to be a lightweight way to introduce templates that can be used within a project to create generated files. PlopJS is a combination of the Handlebars templating language and Inquirer.js for collecting user input. I wrote a more in-depth walkthrough of how and why I used plop to automate file creation.

This work is a derivitive of Is It Worth the Time? by xkcd and is licensed by CC BY-NC 2.5
Documenting within a project
In-line comments can provide valuable context to yourself or other contributors. Comments can be useful for explaining the why behind programming decisions and conventions. For example, it’s a way to explain the reasoning behind variable names that otherwise might otherwise sound arbitrary. Of course, using meaningful variable names—and avoiding generic names like foo, bar, x, y, etc.—can also be a form of documentation. I can often make my comments more concise while refactoring my code by taking time to actively revisit all the variables determining if there is a name that would more clearly describe what the variable represents. It can be especially nice to refactor variable names in the review stage when there is good unit test coverage and/or a type system like Typescript to warn when something was inadvertently broken while refactoring, for example when forgetting to update the value in a particular section of the code.
How verbose and descriptive your comments are should reflect the intended audience. The comments that would be most useful in a work setting may be less verbose and include more business context than the comments one would write for tutorials or open-source projects with a wide variety of contributors in which a more detailed description of the functionality would be more appropriate. It's also important to cleanly remove outdated code instead of commenting it out as one of the benefits of writing software with version control is that you can easily retrieve an earlier version of the codebase within a few minutes.
You can make task-oriented comments more useful by appending phrases like TODO, FIXME, etc. This convention for writing task-oriented comments will allow you to easily track what work needs to be done in the future so that you can focus on the primary task at hand while quickly noting any relevant context for future refactors and enhancements in an appropriate location. Having a consistent way of flagging these types of comments helps make them easier to surface both by humans and by automated tasks. There are also plugins for various IDEs and text editors that can pattern match on the AST to surface TODOs to make them more visible like Todo Tree and TODO Highlight for Visual Studio Code. When using these keyword comments it’s best to have a system in place to clean up the comments and ensure that they are scoped into work so that they can be worked on in the future as opposed to contributing to a growing list of technical debt. If you are in the midst of working on a feature, another way to flag something as a work in progress is to write a failing test that should pass once the appropriate functionality is implemented. This makes it clear what the next step should be if you have to switch tasks for a meeting or to wrap up the day as a failed test allows you to quickly see where you last left off.
Maintaining code-based documentation can be an effective way to improve productivity and reduce the amount of time that it takes to ensure that documentation is up-to-date since the documentation lives much closer to the actual code implementation.
Having to spend less time having to consciously think about enforcing or following particular software conventions will provide you with more time to spend documenting information that can’t be easily automated and allows you to be able to spend more time reflecting on your accomplishments and ensuring they are properly documented. In the next article in this series we will discuss the importance of ensuring that you are regularly documenting your wins with a level of detail and perspective that only you can provide.
If you want to learn more about this topic, check out the rest of my series focusing on document-driven growth:



{kind=link}