- 不涉及docker安装
- 省略主机和容器的切换、容器和容器的切换
- 简写文件的写入,
vim命令后面的部分都为要写进文件的 - 只写了一些必要的测试和验证
- 不具体描述命令细节
宿主机
# 配置虚拟网络
docker network create --subnet=172.18.0.0/16 clusternetwork
docker network ls宿主机
# 创建base容器
docker run -itd --name base --net clusternetwork --ip 172.18.0.2 --privileged=true centos:7 init
# 拷贝软件包目录到容器
docker cp 软件包目录 base:/optbase容器
# 安装必要工具
# net-tools:提供了一些基本的网络工具,如ifconfig、netstat等
# openssh-server:为SSH服务器提供支持,允许远程登录到系统
# openssh-clients:提供了SSH客户端工具,可以连接到其他机器上的SSH服务器
# initscripts:提供了一些启动脚本,用于控制系统服务的启动和停止
# vim:一个文本编辑器
# ntp: 用于同步计算机时钟的协议的实现
# rsync: 用于文件同步
yum install net-tools openssh-server openssh-clients initscripts vim ntp rsync -y
# 修改时区
# 时区自动修改脚本
vim /etc/profile.d/set_time.shTZ='Asia/Shanghai'; export TZ# 应用脚本
source /etc/profile
# 测试
date
# 配置SSH服务器
# 设置监听地址和监听端口
# 允许通过root用户SSH 登录到服务器
vim /etc/ssh/sshd_configPort 22
ListenAddress 0.0.0.0
ListenAddress ::
PermitRootLogin yes# 配置SSH客户端
# 允许通过输入用户名和密码来进行 SSH 登录
vim /etc/ssh/ssh_configPasswordAuthentication yes# 配置NTP
# 屏蔽默认server,设置master为本地时钟源,服务器层级设为10
vim /etc/ntp.conf server 127.127.1.0
fudge 127.127.1.0 stratum 10# NTP开机自启动
systemctl enable ntpd
# rsync开机自启动
systemctl enable rsyncd
# 准备模块目录
mkdir -p /opt/module/
# 安装java
# 解压
cd /opt/software/
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /opt/module/
# 配置环境变量
vim /etc/profile.d/java.sh# java
export JAVA_HOME=/opt/module/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin# 重载环境变量
source /etc/profile
# 测试
java
javac
# 安装scala
# 解压
cd /opt/software/
tar -xvf scala-2.12.10.tgz -C /opt/module/
# 配置环境变量
vim /etc/profile.d/scala.sh# scala
export SCALA_HOME=/opt/module/scala-2.12.10
export PATH=$PATH:$SCALA_HOME/bin# 重载环境变量
source /etc/profile
# 测试
scala -version
# 设置密码
passwd宿主机
# 停止容器
docker stop base
# 提交base为容器centos:base
docker commit -m "base for everything" base centos:base宿主机
docker run -itd --name master-base --net clusternetwork --ip 172.18.0.10 --privileged=true centos:base init
docker run -itd --name slave1-base --net clusternetwork --ip 172.18.0.11 --privileged=true centos:base init
docker run -itd --name slave2-base --net clusternetwork --ip 172.18.0.12 --privileged=true -v /sys/fs/cgroup:/sys/fs/cgroup centos:base initmaster-base
# 修改hosts
# 添加hosts,删除重复同ip的host
vim /etc/hosts172.18.0.10 master
172.18.0.11 slave1
172.18.0.12 slave2# 测试
ping master
ping slave1
ping slave2
# 存入中介文件
touch /etc/hosts.temp
cat /etc/hosts > /etc/hosts.temp
# /etc/hosts文件自动修改脚本
vim /etc/profile.d/hosts.shcat /etc/hosts.temp > /etc/hosts# 没有设置ssh免密登录,无法启动HDFS和YARN服务
ssh-keygen
# 将公钥复制到所有节点的authorized_keys文件
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2slave1-base
# 添加hosts,删除重复同ip的host
vim /etc/hosts172.18.0.10 master
172.18.0.11 slave1
172.18.0.12 slave2# 测试
ping master
ping slave1
ping slave2
# 存入中介文件
touch /etc/hosts.temp
cat /etc/hosts > /etc/hosts.temp
# /etc/hosts文件自动修改脚本
vim /etc/profile.d/hosts.shcat /etc/hosts.temp > /etc/hosts# 将master作为NTP服务器
ntpdate master
# 没有设置ssh免密登录,无法启动HDFS和YARN服务
ssh-keygen
# 将公钥复制到所有节点的authorized_keys文件
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2slave2-base
# 修改hosts
# 添加hosts,删除重复同ip的host
vim /etc/hosts172.18.0.10 master
172.18.0.11 slave1
172.18.0.12 slave2# 测试
ping master
ping slave1
ping slave2
# 存入中介文件
touch /etc/hosts.temp
cat /etc/hosts > /etc/hosts.temp
# /etc/hosts文件自动修改脚本
vim /etc/profile.d/hosts.shcat /etc/hosts.temp > /etc/hosts# 将master作为NTP服务器
ntpdate master
# 没有设置ssh免密登录,无法启动HDFS和YARN服务
ssh-keygen
# 将公钥复制到所有节点的authorized_keys文件
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2master-base
# 准备自定义命令目录
mkdir -p /opt/bin
# 配置环境变量
vim /etc/profile.d/diy_shell.shexport PATH=$PATH:/opt/bin# 重载环境变量
source /etc/profile
# 配置xsync
# 创建xsync文件
vim /opt/bin/xsync#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname="$p1"
echo fname=$fname
#3 获取上级目录到绝对路径
#pdir=$(dirname $(pwd))
pdir=`cd -P $(dirname $p1); pwd`
#pdir=$(pwd)
#pdir=$(cd -P $dirname p1; pwd)
#pdir= $(pwd)
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环,这里host根据自己的节点数和主机名设置
for i in slave1 slave2; do
echo $pdir/$fname $user@$i:$pdir
echo --------------- $i ----------------
rsync -rvl $pdir/$fname $user@$i:$pdir
donecd /opt/bin
chmod u+x xsync宿主机
docker stop master-base
docker stop slave1-base
docker stop slave2-base
docker commit -m "base for all master" master-base centos:master-base
docker commit -m "base for all slave1" slave1-base centos:slave1-base
docker commit -m "base for all slave2" slave2-base centos:slave2-base宿主机
docker run -itd --name master --net clusternetwork --ip 172.18.0.10 --privileged=true centos:master-base init
docker run -itd --name slave1 --net clusternetwork --ip 172.18.0.11 --privileged=true centos:slave1-base init
docker run -itd --name slave2 --net clusternetwork --ip 172.18.0.12 --privileged=true -v /sys/fs/cgroup:/sys/fs/cgroup centos:slave2-base init
# mysql
# Redis
# Azkaban
docker commit -m "master for training" master centos:master
docker commit -m "slave1 for training" slave1 centos:slave1
docker commit -m "slave2 for training" slave2 centos:slave2
宿主机
docker run -itd --name master-hadoop --net clusternetwork --ip 172.18.0.10 --privileged=true centos:master init
docker run -itd --name slave1-hadoop --net clusternetwork --ip 172.18.0.11 --privileged=true centos:slave1 init
docker run -itd --name slave2-hadoop --net clusternetwork --ip 172.18.0.12 --privileged=true -v /sys/fs/cgroup:/sys/fs/cgroup centos:slave2 init查看专题 (选用HA)
docker commit -m "hadoop ha cluster installed" master-hadoop centos:master-hadoop
docker commit -m "hadoop ha cluster installed" slave1-hadoop centos:slave1-hadoop
docker commit -m "hadoop ha cluster installed" slave2-hadoop centos:slave2-hadoopmaster
# 解压缩
cd /opt/software
tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module
# 配置环境变量
vim /etc/profile.d/spark.sh# spark
export SPARK_HOME=/opt/module/spark-3.1.1-bin-hadoop3.2
export PATH=$SPARK_HOME/bin:$PATHsource /etc/profile
# 修改配置文件
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
# 配置spark守护进程环境变量
# JAVA_HOME 在当前环境是多余的,但这是个好习惯
# SCALA_HOME 在当前环境是多余的,但这是个好习惯
# HADOOP_CONF_DIR hadoop的配置目录
# YARN_CONF_DIR yarn的配置目录
vim spark-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_171
export SCALA_HOME=/opt/module/scala-2.12.10
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3
export YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoopcp spark-defaults.conf.template spark-defaults.conf
# 配置spark的默认选项
# spark.master spark集群的模式
vim spark-defaults.confspark.master yarn# 上传到集群
#测试
spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.1.jar 100# 解压
cd /opt/software
tar -zxvf flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/
# 配置环境变量
# HADOOP_CLASSPATH flink 需要hadoop的类地址
# HADOOP_CONF_DIR 需要yarn或者hadoop的配置目录(非必须)
vim /etc/profile.d/flink.sh# flink
export FLINK_HOME=/opt/module/flink-1.14.0
export PATH=$PATH:$FLINK_HOME/binvim /etc/profile.d/hadoop.shexport HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopsource /etc/profile
cd $FLINK_HOME/conf
# 修改flink的配置文件
# 类加载器泄漏检查
vim flink-conf.yamlclassloader.check-leaked-classloader: falsevim workersmaster
slave1
slave2分布到集群
# 测试
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar查看专题
slave2
# 安装epel源和wget
yum -y install epel-release wget
# 下载mysql
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
# 安装源
rpm -ivh mysql57-community-release-el7-8.noarch.rpm
# 安装mysql
yum -y install mysql-community-server --nogpgcheck
# 开启服务
systemctl start mysqld
# 开机自启
systemctl enable mysqld
# 获取12位随机密码
grep "temporary password" /var/log/mysqld.log
# 输入密码,进入mysql shell
mysql -uroot -p
# 设置密码强度为低级(”Query OK“为成功,下同)
set global validate_password_policy=0;
# 设置密码长度最低为4
set global validate_password_length=4;
# 修改本地密码
alter user 'root'@'localhost' identified by '123456';
# 退出
exit
# 开启远程登录
mysql -uroot -p123456
# 创建用户(用于远程登录)
create user 'root'@'%' identified by '123456';
# 允许远程连接
grant all privileges on *.* to 'root'@'%' with grant option;
# 刷新权限
flush privileges;
# 退出
exit# 解压
cd /opt/software
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module
vim /etc/profile.d/hive.sh#hive
export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATHsource /etc/profile
cd $HIVE_HOME/conf
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
vim hive-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_171
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export HIVE_CONF_DIR=/opt/module/apache-hive-3.1.2-bin/conf# 编辑hive配置文件
# javax.jdo.option.ConnectionURL: 指定数据存储的 JDBC 连接 URL
# javax.jdo.option.ConnectionDriverName: 指定用于连接到数据存储的 JDBC 驱动程序类的名称
# javax.jdo.option.ConnectionUserName: 指定连接到数据存储时用于身份验证的用户名
# javax.jdo.option.ConnectionPassword: 指定连接到数据存储时用于身份验证的密码
# system:java.io.tmpdir: 一个属性(property),用来引用临时文件目录路径,系统级别的
# system:user.name: 同理
# jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false
# 表示数据存储是运行在名为 "slave2" 的服务器上,端口号为 3306,使用的数据库名称为 "hive" 的 MySQL 数据库。createDatabaseIfNotExist 参数确保如果数据库不存在,则会创建该数据库。characterEncoding=UTF-8 指定连接所使用的字符编码
vim hive-site.xml<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>system:java.io.tmpdir</name>
<value>/var/hadoop/hive/iotmp</value>
</property>
<property>
<name>system:user.name</name>
<value>root</value>
</property>修复字符问题
vim 命令模式跳转到3215行
: 3215
找到删除字符93-96
删除前:locks fortransactional tables
删除后:locks for transactional tables
# guava版本冲突
rm /opt/module/apache-hive-3.1.2-bin/lib/guava-19.0.jar
cp /opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/guava-27.0-jre.jar /opt/module/apache-hive-3.1.2-bin/lib/
cd /opt/software
tar -zxvf mysql-connector-java-5.1.47.tar.gz
cd mysql-connector-java-5.1.47
cp mysql-connector-java-5.1.47-bin.jar $HIVE_HOME/lib
schematool -dbType mysql -initSchema准备自定义命令目录
mkdir -p /opt/bin
# 配置环境变量
vim /etc/profile.d/diy_shell.shexport PATH=$PATH:/opt/binsource /etc/profile安装c语言环境
yum install -y gcc gcc-c++ make tcl提高gcc版本到5以上
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
vim /etc/profile.d/enable_ds9.sh source /opt/rh/devtoolset-9/enablesource /etc/profile
cd /opt/software
tar -zxvf redis-6.2.6.tar.gz -C /opt/module/
cd /opt/module/redis-6.2.6
make
vim redis.confbind 0.0.0.0
protected-mode no
daemonize yesln -s /opt/module/redis-6.2.6/src/redis-server /opt/bin/redis-server
ln -s /opt/module/redis-6.2.6/src/redis-cli /opt/bin/redis-cli# 解压
cd /opt/software
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/module
# 配置环境变量
vim /etc/profile.d/flume.sh# flume
export FLUME_HOME=/opt/module/apache-flume-1.9.0-bin
export PATH=$PATH:$FLUME_HOME/bin# 应用环境变量
source /etc/profile# 配置flume的运行环境变量
cd $FLUME_HOME/conf
cp flume-env.sh.template flume-env.sh
vim flume-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_171# 测试
flume-ng version
题目
cd $FLUME_HOME/conf
vim spool-to-hdfs.confagent.sources = execSrc
agent.channels = memoryChannel
agent.sinks = hdfsSink
agent.sources.execSrc.type = exec
agent.sources.execSrc.command = tail -F /opt/module/hadoop-3.1.3/logs/hadoop-root-namenode-fc318ea32605.log
agent.channels.memoryChannel.type = memory
agent.channels.memoryChannel.capacity = 10000
agent.channels.memoryChannel.transactionCapacity = 100
agent.sinks.hdfsSink.type = hdfs
agent.sinks.hdfsSink.hdfs.path=hdfs://mycluster/flume
agent.sinks.hdfsSink.hdfs.fileType = DataStream
agent.sources.execSrc.channels = memoryChannel
agent.sinks.hdfsSink.channel = memoryChannel
rm /opt/module/apache-flume-1.9.0-bin/lib/guava-11.0.2.jar
flume-ng agent --conf conf --conf-file $FLUME_HOME/conf/spool-to-hdfs.conf --name agent -Dflume.root.logger=INFO,console
hdfs dfs -ls /flumemaster-hadoop
# 解压
cd /opt/software
tar -zxvf kafka_2.12-2.4.1.tgz -C /opt/module/
# 配置环境变量
vim /etc/profile.d/kafka.sh# kafka
export KAFKA_HOME=/opt/module/kafka_2.12-2.4.1
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile
cd $KAFKA_HOME/config
vim server.propertiesbroker.id=0
listeners=PLAINTEXT://master:9092
zookeeper.connect=master:2181,slave1:2181,slave2:2181# 分发到集群slave1
cd $KAFKA_HOME/config
vim server.propertiesbroker.id=1
listeners=PLAINTEXT://slave1:9092slave2
cd $KAFKA_HOME/config
vim server.propertiesbroker.id=2
listeners=PLAINTEXT://slave2:9092slave1-hadoop
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.propertiesslave2-hadoop-volume
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.propertiesmaster-hadoop
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
# 验证
zkCli.shls /brokers/ids
quit# 新建topic 名为installtopic 分区数为2,副本数为2
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --partitions 2 --replication-factor 2 --topic installtopicslave2
# 初始化azkaban数据库
# 解压
cd /opt/software
tar -zxvf azkaban-db-0.1.0-SNAPSHOT.tar.gz -C /opt/module/
mysql -uroot -p123456# 创建Azkaban数据库
create database azkaban;
# 创建Azkaban用户,任何主机都可以访问Azkaban,密码是123456
CREATE USER 'azkaban'@'%' IDENTIFIED BY '123456';
# 赋予Azkaban用户增删改查权限
GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;
use azkaban;
source /opt/module/azkaban-db-0.1.0-SNAPSHOT/create-all-sql-0.1.0-SNAPSHOT.sql;
exit# 更改MySQL包大小;防止Azkaban连接MySQL阻塞
# 在[mysqld]下面加一行max_allowed_packet=1024M
vim /etc/my.cnfmax_allowed_packet=1024M# 重启MySQL
systemctl restart mysqldmaster-hadoop
# azkaban执行器
# 解压
cd /opt/software
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C /opt/module/
vim /etc/profile.d/azkaban_exec.sh# azkaban exec server
export AZKABAN_EXEC_HOME=/opt/module/azkaban-exec-server-0.1.0-SNAPSHOT
export PATH=$AZKABAN_EXEC_HOME:$PATHsource /etc/profile
vim $AZKABAN_EXEC_HOME/conf/azkaban.propertiesdefault.timezone.id=Asia/Shanghai
azkaban.webserver.url=http://master:8081
mysql.host=slave2
mysql.password=123456
executor.metric.reports=true
executor.metric.milisecinterval.default=60000# 发布到集群
# 解压
cd /opt/software
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C /opt/module/
vim /etc/profile.d/azkaban_web.sh# azkaban web server
export AZKABAN_WEB_HOME=/opt/module/azkaban-web-server-0.1.0-SNAPSHOT
export PATH=$AZKABAN_WEB_HOME:$PATHsource /etc/profile
vim $AZKABAN_WEB_HOME/conf/azkaban.propertiesdefault.timezone.id=Asia/Shanghai
mysql.host=slave2
mysql.password=123456
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatusmaster
cd $AZKABAN_EXEC_HOME
bin/start-exec.sh
curl -G "localhost:$(<$AZKABAN_EXEC_HOME/executor.port)/executor?action=activate" && echoslave1
cd $AZKABAN_EXEC_HOME
bin/start-exec.sh
curl -G "localhost:$(<$AZKABAN_EXEC_HOME/executor.port)/executor?action=activate" && echoslave2
cd $AZKABAN_EXEC_HOME
bin/start-exec.sh
curl -G "localhost:$(<$AZKABAN_EXEC_HOME/executor.port)/executor?action=activate" && echomaster
cd $AZKABAN_WEB_HOME
bin/start-web.sh# 安装maven
# 解压
cd /opt/software/
tar -zxvf apache-maven-3.9.2-bin.tar.gz -C /opt/module/
vim /etc/profile.d/maven.sh# maven
export M2_HOME=/opt/module/apache-maven-3.9.2
export PATH=$PATH:$M2_HOME/binsource /etc/profile# 添加到<mirrors></mirrors>
vim $M2_HOME/conf/settings.xml <mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror># 编译
# 解压
cd /opt/software/
tar -zxvf hudi-release-0.12.0.tar.gz -C /opt/module/
cd /opt/module/hudi-release-0.12.0/源码与hadoop3的兼容问题
vim hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
: 110 跳转至110行
将FSDataOutputStream(baos)
改为FSDataOutputStream(baos, null)
原因:在hadoop2中,FSDataOutputStream构造器是单参的,
而在hadoop3中,FSDataOutputStream的构造器是双参的
jetty依赖冲突问题
父项目指定了jetty版本
而在这两个子项目中,都使用了Hive依赖,带来了不同版本的jetty版本,作为间接依赖
造成了依赖冲突
使用时,Hive带来的jetty被优先使用,造成了一些报错
例如: NoSuchMethodError: org.apache.jetty.server.session.SessionHandler.setHttpOnly(Z)V
原因是Hudi用了jetty 9.4,而Hive带来的jetty是jetty 9.3的。
jetty 9.3的setHttpOnly是无参方法jetty 9.4的setHttpOnly有一个布尔类型的参数
尝试使用默认的Hive版本,减少步骤
在使用时,并不与hive关联,可以无视hive版本
使用默认的Hive版本
在使用时,出现了报错java.lang.NoClassDefFoundError: org/eclipse/jetty/util/component/Graceful与此ERROR相同
原因:
Hudi0.12.0默认的Hive版本为2.3.1,使用的是 Jetty 9.2.x。在使用Hudi-Spark-bundle时,要用到org.eclipse.jetty.util.component.Graceful类。而org.eclipse.jetty.util.component.Graceful类是在 Jetty 9.3.0 版本中引入的。同样也会遇到Jetty版本兼容问题
因此即使使用默认的jetty版本,也需要解决依赖冲突
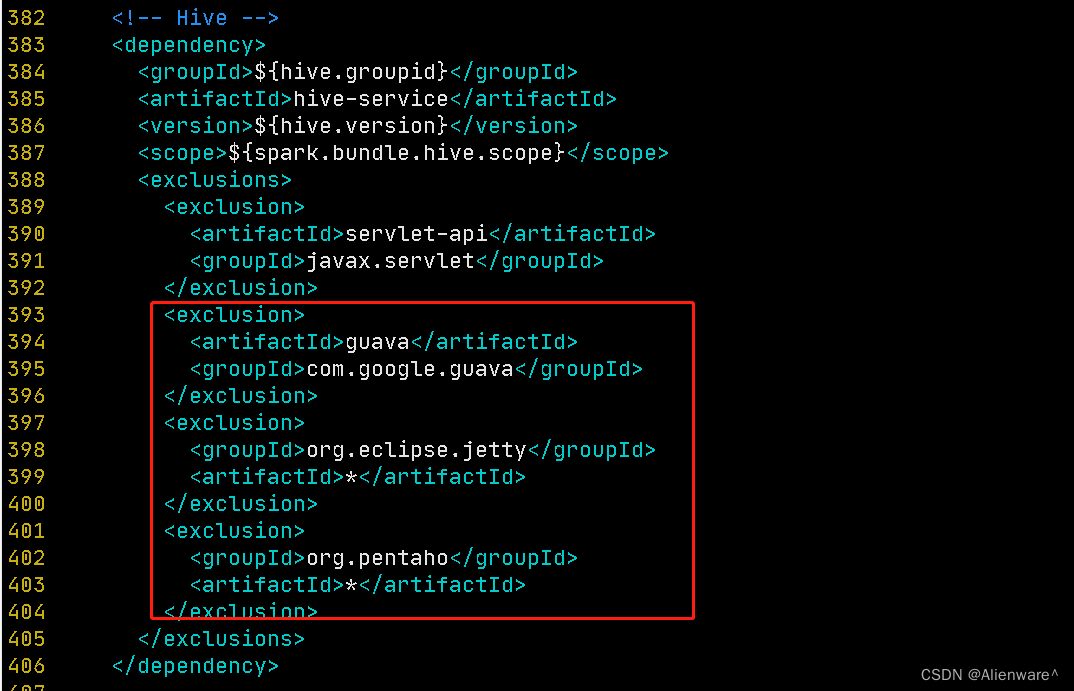
vim packaging/hudi-spark-bundle/pom.xml<!-- Hive -->
<!-- hive-service -->
<!-- 增加的依赖排除 -->
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
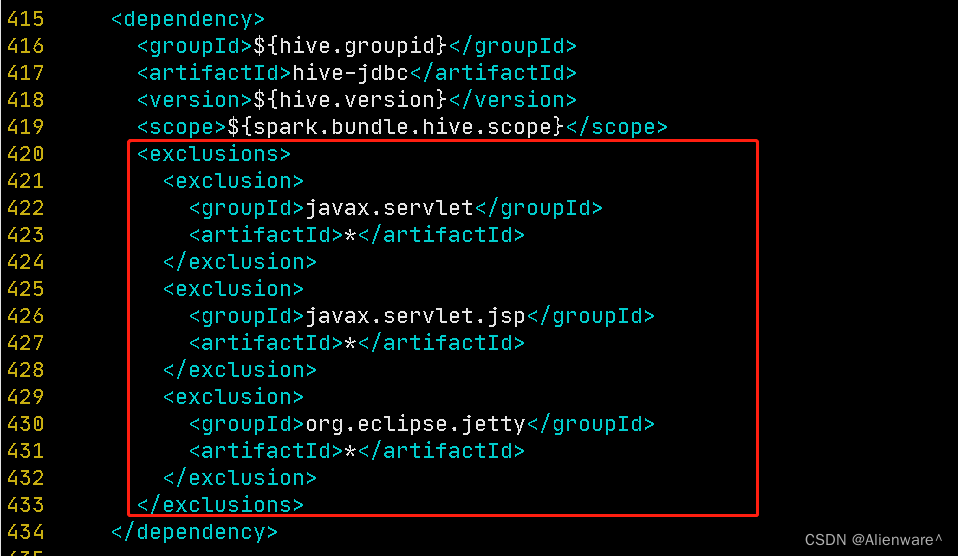
<!-- hive-jdbc -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
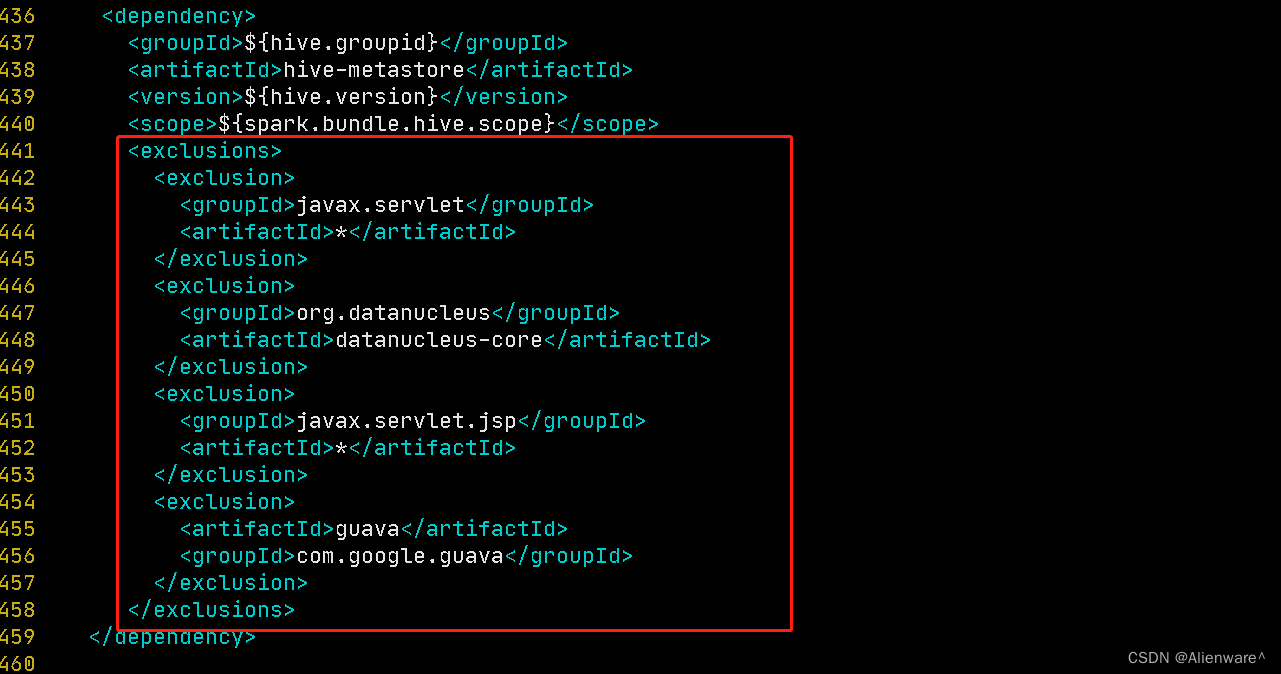
<!-- hive-metastore -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
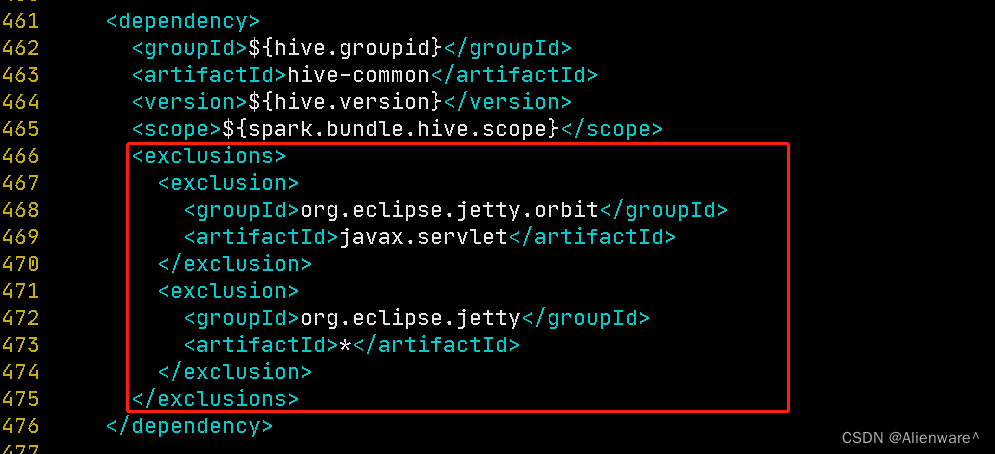
<!-- hive-common -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
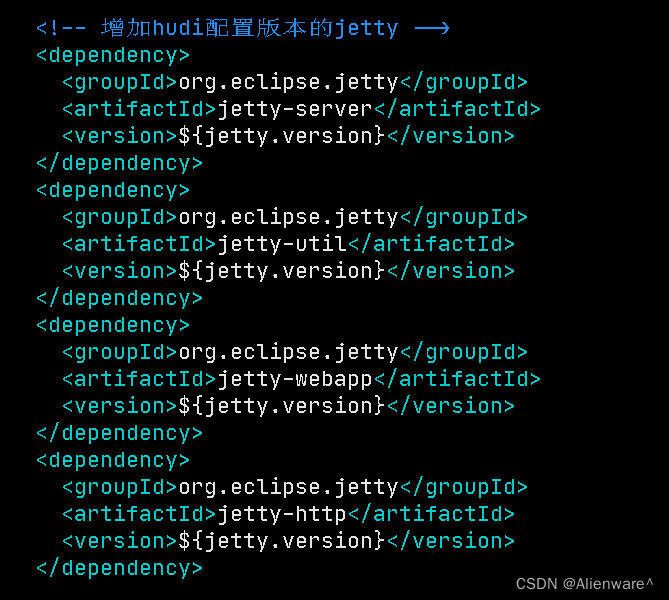
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>修改后
vim packaging/hudi-utilities-bundle/pom.xml<!-- Hive -->
<!-- hive-service -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!-- hive-jdbc -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!-- hive-metastore -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
<!-- hive-common -->
<!-- 增加的依赖排除 -->
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>改后
# 在<repositories>中,声明Aliyun仓库
vim pom.xml<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public </url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>mvn clean package -DskipTests -Dspark3.1 -Dscala-2.12 -Dhadoop.version=3.1.3 -Dhive.version=3.1.2
# 报错了重试一次,可能是网络问题(讲个笑话,用不用aliyun仓库,没有出现网络问题,用了以后,用一次出一次,但是重下几次总能下成功)# 集成到spark
/opt/module/hudi-release-0.12.0/packaging/hudi-spark-bundle/target
cp hudi-spark3.1-bundle_2.12-0.12.0.jar $SPARK_HOME/jars
cd $SPARK_HOME/jars
# 上传到集群
# 运行
spark-shell --master local \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
:quitclickhouse 离线安装
# 解压tgz
mkdir -p /opt/module/clickhouse
cd /opt/software/
# 解压安装程序
tar -zxvf clickhouse-common-static-21.9.4.35.tgz -C /opt/module/clickhouse
tar -zxvf clickhouse-common-static-dbg-21.9.4.35.tgz -C /opt/module/clickhouse
tar -zxvf clickhouse-server-21.9.4.35.tgz -C /opt/module/clickhouse
tar -zxvf clickhouse-client-21.9.4.35.tgz -C /opt/module/clickhouse
cd /opt/module/clickhouse
# 执行安装程序
# server 安装时,会设置default用户的密码
clickhouse-common-static-21.9.4.35/install/doinst.sh
clickhouse-common-static-dbg-21.9.4.35/install/doinst.sh
clickhouse-server-21.9.4.35/install/doinst.sh
clickhouse-client-21.9.4.35/install/doinst.shrm /etc/clickhouse-server/config.d/listen.xml
# 题目上要求删除副配置文件,直接修改主配置文件
# ps: 如果是个人使用,本人并不推荐此做法。
# clickhouse支持多文件配置
# 主配置文件不应当被直接修改,容易造成无法挽回的后果
chmod u+w /etc/clickhouse-server/config.xml
# 修改监听地址和端口
vim /etc/clickhouse-server/config.xml<listen_host>0.0.0.0</listen_host>
<tcp_port>9001</tcp_port>systemctl start clickhouse-server
# 使用客户端连接
clickhouse-client --port 9001 --password 123456 hosts方案
Docker容器如何修改/etc/hosts文件
spark
spark3.1.1安装(spark on yarn)
安装spark3.0.0
spark 报 Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
WARN cluster.YarnScheduler: Initial job has not accepted any resources
Spark的一些问题
MySQL
安装MySQL
slave2 上安装 mysql server
两种安装方式:
########################################################################
方法一:
安装了epel源和wget
yum -y install epel-release wget
下载mysql
wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
安装源
rpm -ivh mysql57-community-release-el7-8.noarch.rpm
查看是否有包:
mysql-community.repo
mysql-community-source.repo
检测方式
cd /etc/yum.repos.d
ls或ll
安装mysql
yum -y install mysql-community-server --nogpgcheck
或
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
yum -y install mysql-community-server
########################################################################
方法二:
安装并配置MySQL
mkdir -p /usr/mysql
tar -xvf /opt/package/mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar -C /usr/mysql
只安装必要包
yum install /usr/mysql/mysql-community-{server,client,common,libs}-*
或安装所有包(多开发包、嵌入式包、测试套件)
*有些版本包含最小客户端和最小服务器,会与客户端和服务端冲突
yum install /usr/mysql/*
########################################################################
开启服务
systemctl start mysqld
开机自启
systemctl enable mysqld
获取12位随机密码
grep "temporary password" /var/log/mysqld.log
设置密码
mysql -uroot -p
输入密码,进入mysql shell
设置密码强度为低级(”Query OK“为成功,下同)
set global validate_password_policy=0;
设置密码长度最低为4
set global validate_password_length=4;
修改本地密码
alter user 'root'@'localhost' identified by '123456';
退出
\q或exit
开启远程登录
mysql -uroot -p123456
创建用户L(用于远程登录)
create user 'root'@'%' identified by '123456';
允许远程连接
grant all privileges on *.* to 'root'@'%' with grant option;
刷新权限
flush privileges;
退出
\q或exit
Hive
HIVE Illegal character entity: expansion character...
BUG guava包版本冲突
Hive启动报错Relative path in absolute URI: xxx
hive启动报错,找不到system:java.io.tmpdir和system:user.name那么
Apache Hive 3.x单机部署
八、hive3.1.2 安装及其配置(本地模式和远程模式)
一些潜在问题:
全网没有解决方法,如果之后照成数据缺失再处理
As above but for "WARN DataNucleus.MetaData:96 - Metadata has jdbc-type of null yet this is not valid. Ignored" messages.
2023-05-24 04:55:50,930 INFO[87948b06-7500-49ce-b899-491d47ff9b5d main] DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
2023-05-24 04:55:52,236 WARN[87948b06-7500-49ce-b899-491d47ff9b5d main] DataNucleus.MetaData: Metadata has jdbc-type of null yet this is not valid. Ignoredredis
安装Redis集群安装
安装c语言环境
yum install -y gcc gcc-c++ make tcl
提高gcc版本到5以上
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
临时切换版本
scl enable devtoolset-9 bash
永久切换版本
echo source /opt/rh/devtoolset-9/enable >> /etc/profile
解压到指定位置
编译
cd /usr/redis/redis-6.2.6
make
测试(可选)
make test
创建Redis相关工作目录
mkdir /usr/redis/redis-cluster/{data/{redis_7000,redis_7001},conf,run,log} -p
复制redis配置文件
cd /usr/redis/redis-6.2.6/
cp redis.conf /usr/redis/redis-cluster/conf/redis_7000.conf
cp redis.conf /usr/redis/redis-cluster/conf/redis_7001.conf
修改redis-master配置文件
vim /usr/redis/redis-cluster/conf/redis_7000.conf
port 7000 #修改redis监听端口
bind 0.0.0.0 #表示redis允许所有地址连接。默认127.0.0.1,仅允许本地连接
daemonize yes #允许redis后台运行
pidfile /usr/redis/redis-cluster/run/redis_7000.pid #pid存放目录
logfile "/usr/redis/redis-cluster/log/redis_7000.log" #设置Sentinel日志存放路径
dir /usr/redis/redis-cluster/data/redis_7000 #工作目录
cluster-enabled yes #是否开启集群
cluster-config-file /usr/redis/redis-cluster/conf/nodes_7000.conf #集群配置文件的名称
cluster-node-timeout 15000 #节点互连超时的阀值。集群节点超时毫秒数,默认15秒
appendonly yes #Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。
requirepass 123456 #设置redis密码
masterauth 123456 #主从同步master的密码(如果没有设置redis密码,则无需配置)
修改redis-slave配置文件
vim /usr/redis/redis-cluster/conf/redis_7001.conf
port 7001
bind 0.0.0.0
daemonize yes
pidfile /usr/redis/redis-cluster/run/redis_7001.pid
logfile "/usr/redis/redis-cluster/log/redis_7001.log"
dir /usr/redis/redis-cluster/data/redis_7001
cluster-enabled yes
cluster-config-file /usr/redis/redis-cluster/conf/nodes_7001.conf
cluster-node-timeout 15000
appendonly yes
requirepass 123456
masterauth 123456
分发到集群其他服务器
scp -r /usr/redis root@slave1:/usr
scp -r /usr/redis root@slave2:/usr
设置软链接,方便启动redis服务
ln -s /usr/redis/redis-6.2.6/src/redis-server /usr/bin/redis-server
ln -s /usr/redis/redis-6.2.6/src/redis-cli /usr/bin/redis-cli
检查软链接是否生效
redis-cli --version
redis-server --version
集群内每台服务器分别启动两个redis
redis-server /usr/redis/redis-cluster/conf/redis_7000.conf
redis-server /usr/redis/redis-cluster/conf/redis_7001.conf
验证是否启动成功
ps -ef | grep redis
创建Redis Cluster
redis-cli -a 123456 --cluster create 172.18.0.10:7000 172.18.0.11:7000 172.18.0.12:7000 172.18.0.10:7001 172.18.0.11:7001 172.18.0.12:7001 --cluster-replicas 1
登录redis集群
redis-cli -a 123456 -h 172.18.0.10 -p 7000 -c
查看集群信息:
登录后输入`cluster info`
查看集群节点列表:
登录后输入`cluster nodes`
查看集群节点列表:
查看集群内主从关系:
redis-cli -a 123456 -h 172.18.0.10 -p 7000 -c cluster slots | xargs -n8 | awk '{print $3":"$4"->"$6":"$7}' | sort -nk2 -t ':' | uniq
关闭redis集群
redis-cli -a 123456 -h 172.18.0.10 -p 7000 shutdown
redis-cli -a 123456 -h 172.18.0.10 -p 7001 shutdown
redis-cli -a 123456 -h 172.18.0.11 -p 7000 shutdown
redis-cli -a 123456 -h 172.18.0.11 -p 7001 shutdown
redis-cli -a 123456 -h 172.18.0.12 -p 7000 shutdown
redis-cli -a 123456 -h 172.18.0.12 -p 7001 shutdown
添加节点
redis-trib.rb add-node 新节点host:port 集群中任意host:port
删除节点
redis-trib.rb del-node 集群中任意host:port 要删除节点id
Flink
xception in thread “Thread-6“ java.lang.IllegalStateException: Trying to access closed classloader.
Hadoop3 ShutdownHookManager visit closed ClassLoader
hadoop3和flink导致的bug,会出现莫名的内存泄漏,不影响使用
Exception in thread “Thread-6“ java.lang.IllegalStateException: Trying to access closed classloader.
flink 运维中遇到的问题_slot request bulk is not fulfillable! could not al_Mumunu-的博客-程序员宅基地
Hadoop3 ShutdownHookManager visit closed ClassLoader
Flink Yarn单机部署 flink-conf.yaml
flink on yarn集群搭建
Flink on Yarn模式部署
flink on yarn的配置及报错处理
其他
flink on yarn并不需要配置jobmanager.rpc.address,jobmanager.rpc.address由运行时,yarn自动分配flink on yarn并不需要配置masters文件,flink on yarn没有master节点这个概念flink1.14后,升级了其 Hadoop 依赖项。不再需要手动下载放入flink-shaded-hadoop-<version>.jar
Flume
flume1.9往hdfs写报错:java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
Hudi
hudi/README.md
Spark Guide
Hudi学习01 -- Hudi简介及编译安装
Hudi编译安装 《==疑似伪原创
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品) 《==这是个视频
ClickHouse
Configuration Files
centos ping ipv6地址,提示: Address family for hostname not supported,
ClickHouse v22.8.5.29-lts 安装笔记
clickhouse 入门之环境搭建(1)