Linux的内存管理分为 虚拟内存管理 和 物理内存管理,本文主要介绍 虚拟内存管理 的原理和实现。在介绍 虚拟内存管理 前,首先介绍一下 x86 CPU 内存寻址的具体过程。
Intel x86 CPU 把内存地址分为3种:逻辑地址、线性地址 和 物理地址。
逻辑地址:也称为虚拟地址,由段寄存器:偏移量组成(段寄存器为16位,偏移量为32位),偏移量是应用程序能够直接操作的地址,比如在C语言中使用&操作符取得的变量地址就是逻辑地址。线性地址:是通过 CPU 的分段单元把段寄存器:偏移量转换成一个32位的无符号整数,范围从0x00000000 ~ 0xFFFFFFFFF。分段机制的原理是,段寄存器指向一个段描述符,段描述符里面包含了段的基地址(开始地址),然后通过基地址加上偏移量就是线性地址。物理地址:内存中的每个字节都由一个32位的整数编号表示,而这个整数编号就是内存的物理地址。比如在安装了4GB内存条的计算机中,能够寻址的物理地址范围为0x00000000 ~ 0xFFFFFFFFF。在开启了分页机制的情况下,线性地址要经过分页单元转换才能得到物理地址。
下图展示了 逻辑地址、线性地址 和 物理地址 三者的关系:

前面介绍过,应用程序中的逻辑地址需要通过分段机制和分页机制转换后才能得到真正的物理地址。由于Linux把代码段和数据段的基地址都设置为0,所以逻辑地址中的偏移量就等价于线性地址。所以这里就不介绍分段机制了,有兴趣可以查阅相关的文章或者书籍。
由于Linux主要使用分页机制,所以下面重点介绍一下分页机制的原理。
由于CPU只能对 物理地址 进行寻址,所以 线性地址 需要映射到 物理地址 才能使用,而映射是按 页(Page) 作为单位进行的,一个页的大小为4KB,所以32位的线性地址可以划分为 2^32 / 2^12 = 2^20 (1048576) 个页。
映射是通过 页表 作为媒介的。页表是一个类型为整型的数组,数组的每个元素保存了线性地址页对应的物理地址页的起始地址。由于32位的线性地址可以划分为 2^20 个页,而每个线性地址页需要一个整型来映射到物理地址页,所以页表的大小为 4 * 2^20 (4MB)。由于并不是所有的线性地址都会映射到物理地址,所以为了节省空间,引入了一个二级管理模式的机器来组织分页单元。如下图:
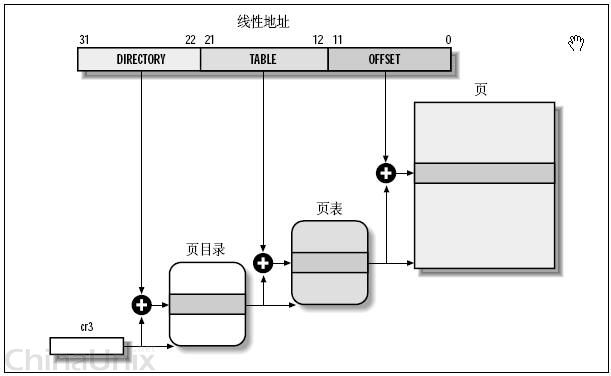
从上图可以看出,线性地址被划分为3部分:面目录索引(10位)、页表索引(10位) 和 偏移量(12位)。而 cr3寄存器 保存了 页目录 的物理地址,这样就可以通过 cr3寄存器 来找到 页目录。页目录项 指向页表地址,页表项 指向映射的物理内存页地址,而 偏移量 指定了在物理内存页的偏移量。
应用程序使用 malloc() 函数向Linux内核申请内存时,Linux内核会返回可用的虚拟内存地址给应用程序。我们可以通过以下程序来验证:
#include <stdio.h>
#include <stdlib.h>
int main()
{
void *ptr;
ptr = malloc(1024);
printf("%p\n", ptr);
return 0;
}运行程序后输出:
# 0x7fffeefe6260
内核返回的是虚拟内存地址,但虚拟内存地址映射到物理内存地址不会在申请内存时进行,只有在应用程序读写申请的内存时才会进行映射。
每个进程都可以使用4GB的虚拟内存地址,所以Linux内核需要为每个进程管理这4GB的虚拟内存地址。例如记录哪些虚拟内存地址是空闲的可以分配的,哪些虚拟内存地址已经被占用了。而Linux内核使用 vm_area_struct 结构进行管理,定义如下:
struct vm_area_struct {
struct mm_struct * vm_mm; /* VM area parameters */
unsigned long vm_start;
unsigned long vm_end;
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned long vm_flags;
/* AVL tree of VM areas per task, sorted by address */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops;
unsigned long vm_pgoff;
struct file * vm_file;
...
};vm_area_struct 结构各个字段作用:
vm_mm:指向进程内存空间管理对象。vm_start:内存区的开始地址。vm_end:内存区的结束地址。vm_next:用于连接进程的所有内存区。vm_page_prot:指定内存区的访问权限。vm_flags:内存区的一些标志。vm_file:指向映射的文件对象。vm_ops:内存区的一些操作函数。
vm_area_struct 结构通过以下方式对虚拟内存地址进行管理,如下图:
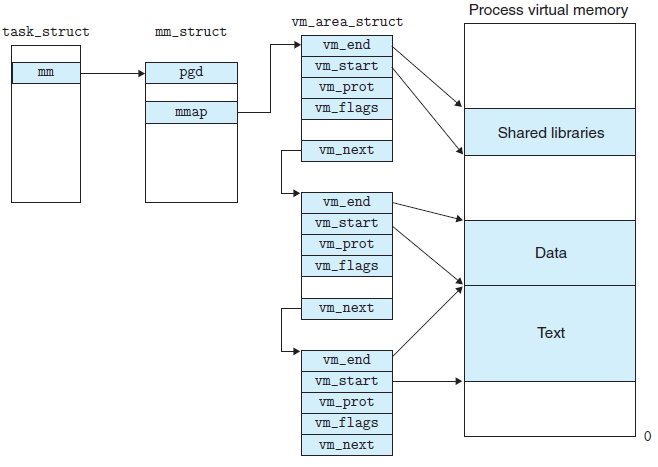
从上图可以看出,通过 vm_area_struct 结构体可以把虚拟内存地址划分为多个用途不相同的内存区,比如可以划分为数据区、代码区、堆区和栈区等等。每个进程描述符(内核用于管理进程的结构)都有一个类型为 mm_struct 结构的字段,这个结构的 mmap 字段保存了已经被使用的虚拟内存地址。
当应用程序通过 malloc() 函数向内核申请内存时,会触发系统调用 sys_brk(),sys_brk() 实现如下:
asmlinkage unsigned long sys_brk(unsigned long brk)
{
unsigned long rlim, retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
down(&mm->mmap_sem);
if (brk < mm->end_code)
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
if (brk <= mm->brk) { // 缩小堆空间
if (!do_munmap(mm, newbrk, oldbrk-newbrk))
goto set_brk;
goto out;
}
// 检测是否超过限制
rlim = current->rlim[RLIMIT_DATA].rlim_cur;
if (rlim < RLIM_INFINITY && brk - mm->start_data > rlim)
goto out;
// 如果已经存在, 那么直接返回
if (find_vma_intersection(mm, oldbrk, newbrk+PAGE_SIZE))
goto out;
// 是否有足够的内存页?
if (!vm_enough_memory((newbrk-oldbrk) >> PAGE_SHIFT))
goto out;
// 所有判断都成功, 现在调用do_brk()进行扩展堆空间
if (do_brk(oldbrk, newbrk-oldbrk) != oldbrk)
goto out;
set_brk:
mm->brk = brk;
out:
retval = mm->brk;
up(&mm->mmap_sem);
return retval;
}sys_brk() 系统调用的 brk 参数指定了堆区的新指针,sys_brk() 首先会进行一些检测,然后调用 do_brk() 函数进行虚拟内存地址的申请,do_brk() 函数实现如下:
unsigned long do_brk(unsigned long addr, unsigned long len)
{
struct mm_struct * mm = current->mm;
struct vm_area_struct * vma;
unsigned long flags, retval;
...
// 如果新申请的内存空间与之前的内存空间相连并且特性一样, 那么就合并内存空间
if (addr) {
struct vm_area_struct * vma = find_vma(mm, addr-1);
if (vma && vma->vm_end == addr &&
!vma->vm_file &&
vma->vm_flags == flags)
{
vma->vm_end = addr + len;
goto out;
}
}
// 新申请一个 vm_area_struct 结构
vma = kmem_cache_alloc(vm_area_cachep, SLAB_KERNEL);
if (!vma)
return -ENOMEM;
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = flags;
vma->vm_page_prot = protection_map[flags & 0x0f];
vma->vm_ops = NULL;
vma->vm_pgoff = 0;
vma->vm_file = NULL;
vma->vm_private_data = NULL;
insert_vm_struct(mm, vma); // 添加到虚拟内存管理器中
out:
...
return addr;
}do_brk() 函数主要通过调用 kmem_cache_alloc() 申请一个 vm_area_struct 结构,然后对这个结构的各个字段进行初始。最后通过调用 insert_vm_struct() 函数把这个结构添加到进程的虚拟内存地址链表中。
为了加速查找虚拟内存区,Linux内核还为
vm_area_struct结构构建了一个AVL树(新版本为红黑树),有兴趣的可以查阅源码或相关资料。
前面说过,虚拟地址必须要与物理地址进行映射才能使用,如果访问了没有被映射的虚拟地址,CPU会触发内存访问异常,并且调用异常处理例程对没被映射的虚拟地址进行映射操作。Linux的内存访问异常处理例程是 do_page_fault(),代码如下:
asmlinkage void do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
...
// 获取发生错误的虚拟地址
__asm__("movl %%cr2,%0":"=r" (address));
...
down(&mm->mmap_sem);
// 查找第一个结束地址比address大的vma
vma = find_vma(mm, address);
if (!vma)
goto bad_area;
...
// 这里是进行物理内存映射的地方
switch (handle_mm_fault(mm, vma, address, write)) {
case 1:
tsk->min_flt++;
break;
case 2:
tsk->maj_flt++;
break;
case 0:
goto do_sigbus;
default:
goto out_of_memory;
}
...
bad_area:
up(&mm->mmap_sem);
bad_area_nosemaphore:
// 用户空间触发的虚拟内存地址越界访问, 发送SIGSEGV信息(段错误)
if (error_code & 4) {
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
info.si_signo = SIGSEGV;
info.si_errno = 0;
info.si_addr = (void *)address;
force_sig_info(SIGSEGV, &info, tsk);
return;
}
}当异常发生时,CPU会把触发异常的虚拟内存地址保存到 cr2寄存器 中,do_page_fault() 函数首先通过读取 cr2寄存器 获取到触发异常的虚拟内存地址,然后调用 find_vma() 函数获取虚拟内存地址对应的 vm_area_struct 结构,如果找不到说明这个虚拟内存地址是不合法的(没有进行申请),所以内核会发送 SIGSEGV 信号(传说中的段错误)给进程。如果虚拟地址是合法的,那么就调用 handle_mm_fault() 函数对虚拟地址进行映射。